Ubuntu Explained: How to ensure security and stability in cloud instances—part 3
Ubuntu updates: securing multiple Ubuntu instances while maximising uptime
Most people know that it is important to apply security updates. It can be challenging, however, to accomplish this while maximising the uptime of the services you are running on top. Every change, even applying security patches, carries some risk of disrupting your workloads. You therefore need to be deliberate about your update strategy.
This blog is the third in a three-part series by John Chittum (Engineering Manager, CPC) and Aaron Whitehouse (Senior Public Cloud Enablement Director). In the first part we covered the philosophy of Ubuntu’s releases, the archive’s structure and how packages are updated. In the second part, we explained how to update individual Ubuntu instances. That background will help you understand what we cover below, so please read those first before continuing.
Ubuntu is a Debian-based Linux distribution which uses two primary package types: snaps and Debian (.deb) packages. Snaps have their own update mechanisms, so this blog series focuses only on the Debian package updates. We aim to give an overview of the best approaches to updating packages across multiple instances. Then you can use this to decide which fit your particular requirements.
Differences between updating single and multiple Ubuntu instances
You can update large fleets of Ubuntu instances in the same way we outlined for single instances in Part 2. If you are worried about service uptime, and have the resources to invest, you have more choices with multiple instances. You may benefit from coordinating your update rollouts to maximise the uptime of your fleet.
We take a number of steps to reduce the risk of updates breaking workloads (see Part 1). It is always possible, however, for an update to have negative consequences in your specific environment. Many of our users with large Ubuntu estates therefore choose to roll out security updates more slowly across production instances. This can let you catch any issues in your environment before the update is widely deployed. The flipside is that it leaves those instances exposed to security vulnerabilities during that rollout period. You need to balance the delay in patching security vulnerabilities against the increased time to notice issues. You should involve your security team in that analysis.
Every production environment is different, but some approaches and things to consider are set out below. If you are managing updates centrally, make sure that you turn off unattended-upgrades on the instances (see Part 2).
Monitoring
Slowing down the rollout of security patches is only likely to help if you will notice if something goes wrong. Do you have automatic health checks in place? Have you set up Observability for your production environments? Do your internal Ubuntu users have a way to let you know if something stops working as expected?
Highly-available services
Imagine a highly-available service that can tolerate one or more instances failing. Updating any one of those instances should be relatively safe. Updating all instances at the same time, however, puts the service at risk.
In such situations you will often want to update related instances one availability zone or update domain at a time. You can monitor updated instances for any impact on your services, ideally with automated health checks. Then, if everything looks as expected, you can roll the update to the next availability zone.
Unattended-upgrades and HA services
These requirements mean that unattended-upgrades will often be a poor choice for such environments. Unattended-upgrades is not fleet aware and updates occur at uncoordinated times regardless of the health of updated instances. It is possible to configure the time that unattended-upgrades runs in /etc/systemd/system/timers.target.wants/apt-daily-upgrade.timer to ensure that not all nodes are updating at the exact same time and spread updates over a time period. Even so, these instances will update with no awareness of the health of instances that have already received the updates. An update that causes issues for you will continue to roll through your production environments unless you manually intervene.
The risks of automated reboot tools with HA services
Similarly, there are tools that will monitor when instances need to be rebooted and to do this for you. Be careful to ensure that these are also aware of your wider estate of instances and their health. An example of an open source service, not associated with Ubuntu, is Kured. Kured is a Kubernetes daemonset that performs automatic node reboots when needed. You can configure Kured to check for active alerts before rebooting additional nodes, but you need to set this up. We have seen update issues in customer environments that only show up on a reboot. Without health checks, something like Kured can make issues on reboot have a much greater impact on your clusters.
Fleet-aware update tools
There are available update management tools for Ubuntu that are fleet aware. Azure’s Guest Patching Service will roll out updates across availability zones and regions over time. It will use health monitoring to try to identify issues with an update and pause the rollout. We have worked closely with the AzGPS team to make Ubuntu support first-class in this tool. Alternatively, it is possible to control the roll-out of Ubuntu updates across public or private clouds with Landscape. Landscape is the Ubuntu systems management tool included as part of Ubuntu Pro.
Staging environments
If you build a service on Ubuntu, you likely have a staging environment for your service. If so, it can make sense to deploy security updates to that environment first. You can then run your workload tests against the updates before deploying them to your production environments.
You can even selectively upgrade dependencies of your service to packages that are still in the -proposed pocket. This lets you test your application or service on updates that have not yet been deployed to the main archives.
Snapshots in time
We update the standard Ubuntu archives on a rolling basis. As new package updates are made available, we include these in the archive. If there is material time in between running updates on different instances, the available updates could be different. It is even possible that two instances could see different updates at the same time because of phased updates. This can make it hard to roll out updates gradually, testing for any issues before rolling them out further.
You can use a number of techniques to create a coherent set, or snapshot, of packages. This allows you to test and roll out the same packages across your production estate over time. If there are any negative effects of the updates in your environment, this limits the impact. It also lets you pause the rollout while you resolve the issues (or seek help from our support team).
APT pinning
You may find guides recommending apt pins to ensure that critical packages are updated only when required and under supervision. This is a powerful tool, however it has a steep learning curve. You need to understand how pins operate and the ramifications of pinning specific packages. In most cases it probably will not be the best option.
Golden images and image-based updates
In some environments, such as Kubernetes worker nodes, it can make sense to use image-based updates or “Golden Images”. This essentially means that you create an operating system image that includes the security updates. You can then test this image, add the updated nodes to your clusters and remove the old, insecure worker nodes. You treat these images as immutable. Instead of applying updates to them in production, you replace them completely with the next verified image. You can increase stability by learning an image building tool and maintaining a CI/CD pipeline for those images. It is important to automate this as much as possible, as any manual delays in the process increase your security exposure for no stability benefit.
Deb package mirrors
An approach used by many of Canonical’s customers is to create internal Ubuntu deb package mirrors. These synchronise a copy of the archives on a specific, periodic basis. Internal instances then point at that mirror, rather than the main Ubuntu archives. Landscape, mentioned earlier, includes features to make managing Ubuntu repositories much simpler. Maintaining a package mirror does have a relatively high cost of infrastructure, as you store at least one copy of all the packages you mirror.
Ubuntu snapshot service
The exciting news is that we have just announced a new snapshot service. This can provide many of the benefits of mirroring archives without the infrastructure cost or setup overhead. This is integrated into APT in Ubuntu 23.10 and is coming soon to 22.04, 20.04 and Ubuntu Pro 18.04. Julian Andres Klode, the maintainer of APT, released a video showing how to use the new snapshot feature:
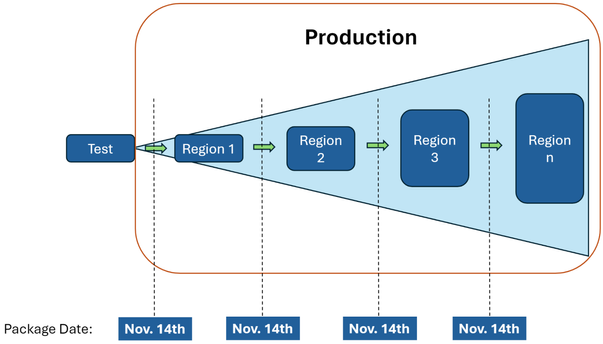
Microsoft is using this service to enable Safe Deployment Practices on Azure. You can learn more about this from the Ubuntu Summit presentation. Microsoft helpfully illustrates this approach in their official announcement. Instead of having a different state of the archive for each region update:
Using snapshots you can have a consistent set of packages being deployed in each region:
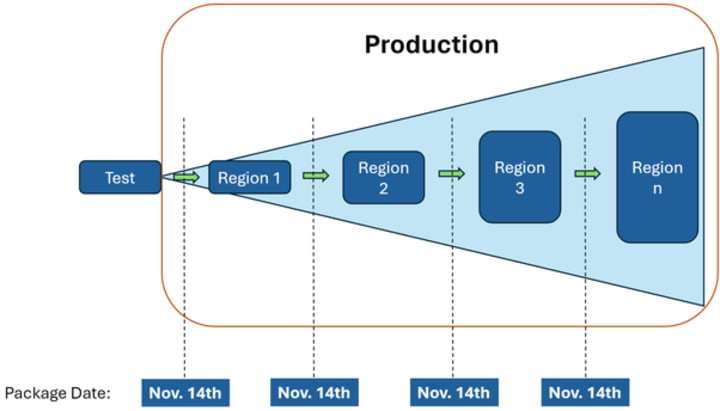
Any of these approaches do mean that you are likely to have more unpatched vulnerabilities in your production estate. You are choosing not to apply available patches beyond the snapshot date. Similarly, you will normally roll this snapshot out to different regions or availability zones gradually over time. That means the last instances will not receive the snapshot of security patches until that rollout is complete. These rollouts should therefore be as short as possible while still giving you time to notice any negative impacts of the updates. You should also review the vulnerabilities fixed in the updates you have not yet applied (USNs and CVEs). You may wish to accelerate your rollout of updates that patch higher-priority CVEs. Ultimately, your organisation needs to balance the risk of delaying security updates against the potential benefits to stability.
Conclusion
If you are running Ubuntu in production, it is crucial that you apply available security updates to your instances. We explained how we reduce the risk that our updates have negative impacts in the first part of this series. People use Ubuntu in so many interesting ways, beyond what even we can imagine. It is therefore impossible to eliminate the risk that an update causes issues somewhere.
If you manage large numbers of Ubuntu instances, particularly in highly-available configurations, you may benefit from controlling your update rollout. You can then roll out updates in a more fleet-aware fashion. By rolling out gradually, you do leave some instances with unpatched security vulnerabilities for longer. The benefit, however, can be limiting the impact of any update on service uptime, pausing rollouts that cause issues. Combined with automation, monitoring and automated health checks, this can increase stability with an acceptable reduction in security.
Managing updates in a distributed environment can be a challenge. There are, however, an increasing number of tools to help you do so. Landscape, part of Ubuntu Pro, includes features to help you manage Ubuntu updates across any public or private cloud. You could use the native APT snapshot integration in your own automation. We have worked with our public cloud partners to make Ubuntu updates work well in their built-in update tooling.
No policy or tool is foolproof, but a deliberate and well-designed update strategy can save you from sleepless nights. By being proactive and making informed decisions, you can ensure that your Ubuntu servers remain secure while protecting service availability.