
Generating images with LocalAI using a GPU
In my last blog post on using code generating LLMs on OpenSUSE, I explained on how to run models on your local machine without utilizing a GPU card. In this post I want to show on how to setup your system in order to make use of an available GPU for running a LocalAI instance to generate your own images with it. Since it is the most popular GPU platform for AI currently, I’ll focus on using an NVIDIA card for this task. As OS I’m using OpenSUSE Tumbleweed, links to documentation for other SUSE products are provided where required. For a more detailed explanation on LocalAI, please see my previous post.
Requirements
Generating images using stable diffusion based models requires quite some performance, and thus a modern compute capable graphics card is highly recommended for this task. The main aspect here is the available VRAM as well as the compute capabilities of the card. A good choice for beginners is e.g. a GTX 4060 Ti model with 12GB VRAM, which was used for testing the instructions below.
In order to use a NVIDIA Graphics Card for LocalAI, the graphics card kernel driver needs to be installed and configured for use from within a docker container.
Driver Installation
For installing the NVIDIA proprietary drivers, comprehensive documentation is available here. If you already have a system with proprietary NVIDIA drivers installed, you can skip this step.
The basic procedure for OpenSUSE Tumbleweed with e.g. a GTX 4060 GPU is as follows (please follow instructions in the linked document above for other SUSE products):
- Add the NVIDIA repository:
zypper addrepo --refresh https://download.nvidia.com/opensuse/tumbleweed NVIDIA && zypper ref
- Install the kernel drivers and user space utils
zypper in nvidia-video-G06 nvidia-gl-G06 nvidia-compute-utils-G06
This will install the following packages:
libnvidia-egl-wayland1 nvidia-compute-G06 nvidia-compute-G06-32bit nvidia-driver-G06-kmp-default nvidia-gl-G06 nvidia-gl-G06-32bit nvidia-video-G06 nvidia-video-G06-32bit nvidia-compute-utils-G06
- Additionally to the driver, I recommend to install the nvtop command line tool, which displays the Memory and GPU usage of the graphics card:
zypper in nvtop
- Once all packages are installed, reboot the system
Docker Configuration
In order to use the graphics card with a docker based deployment of LocalAI, some additional packages, mainly the nvidia-container-toolkit need to be installed and configured. A detailed description can be found here, for OpenSUSE Tumbleweed:
- Add the NVIDIA repository and enable the experimental packages
sudo zypper ar https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo sudo zypper modifyrepo --enable nvidia-container-toolkit-experimental
- Install the nividia-container-toolkit
sudo zypper --gpg-auto-import-keys install -y nvidia-container-toolkit
- Configure the the toolkit and docker to work for a normal user
nvidia-ctk runtime configure --runtime=docker --config=$HOME/.config/docker/daemon.json sudo systemctl restart docker nvidia-ctk config --set nvidia-container-cli.no-cgroups --in-place
- Additionally, it is required to edit
/etc/nvidia-container-runtime/config.toml
and replace under
[nvidia-container-cli]
no-cgroups = true
with
no-cgroups = false
- Test if docker containers can use the nvidia runtime
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
You should see output looking like this:
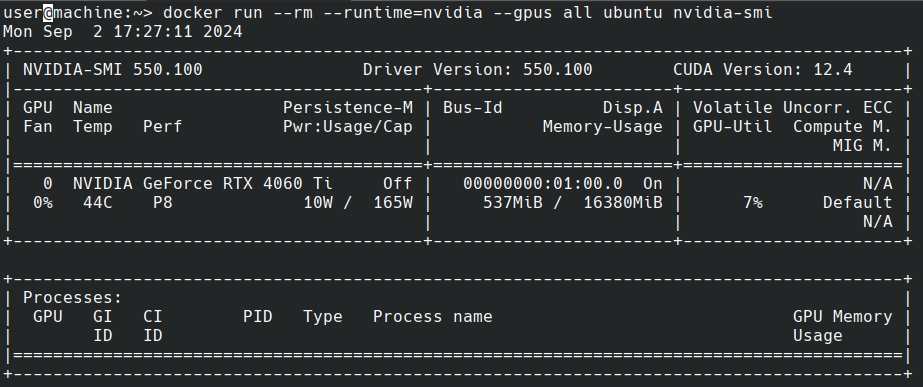
With now GPU acceleration working for docker containers, it’s time to install LocalAI. Other then in the last post, I’ll this time use the All in One containers, as they come with CUDA support and pre installed models to test the setup.
Installation
- Create a directory to store the docker compose file and the models and change into it
mkdir LocalAI cd LocalAI/
- create a docker-compose.yaml file with the following content
services:
api:
image: localai/localai:latest-aio-gpu-nvidia-cuda-12
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/readyz"]
interval: 1m
timeout: 10m
retries: 20
ports:
- 8080:8080
environment:
- DEBUG=true
- MODELS_PATH=/models
- SINGLE_ACTIVE_BACKEND=true
- PARALLEL_REQUESTS=false
- WATCHDOG_IDLE=true
- WATCHDOG_BUSY=true
- WATCHDOG_IDLE_TIMEOUT=50m
- WATCHDOG_BUSY_TIMEOUT=50m
volumes:
- ./models:/models:cached
docker-compose up
Watch the console output, once the containers are downloaded and starting, you should see output confirming that the GPU is used
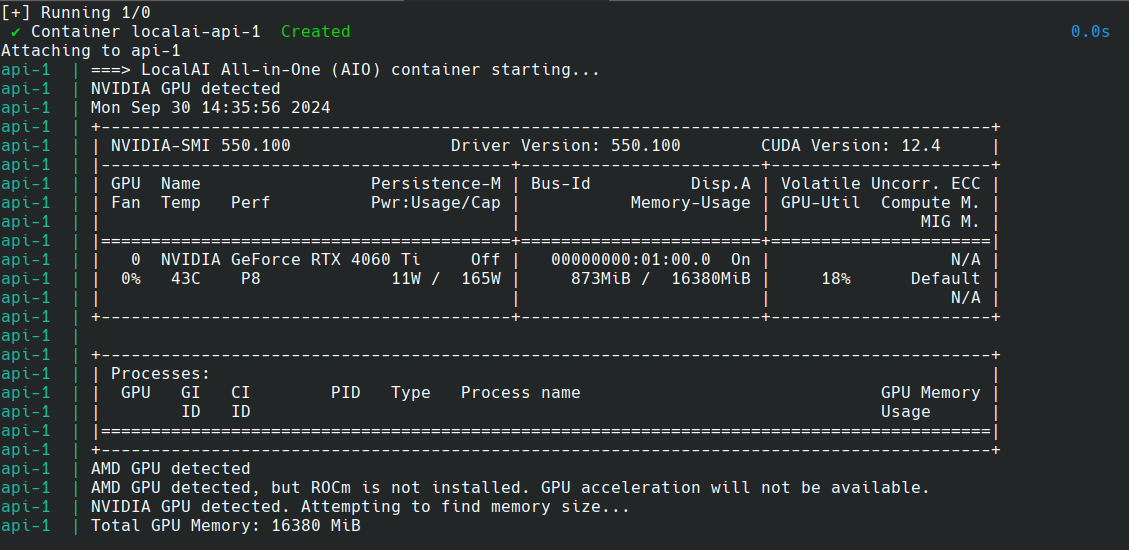
Next, LocalAI downloads all required models. This can take some time, so be patient.
Once all models have finished downloading, you can start generating images right away, using the preconfigured stablediffusion module.
- To monitor the GPU memory utilization, start nvtop
~> nvtop
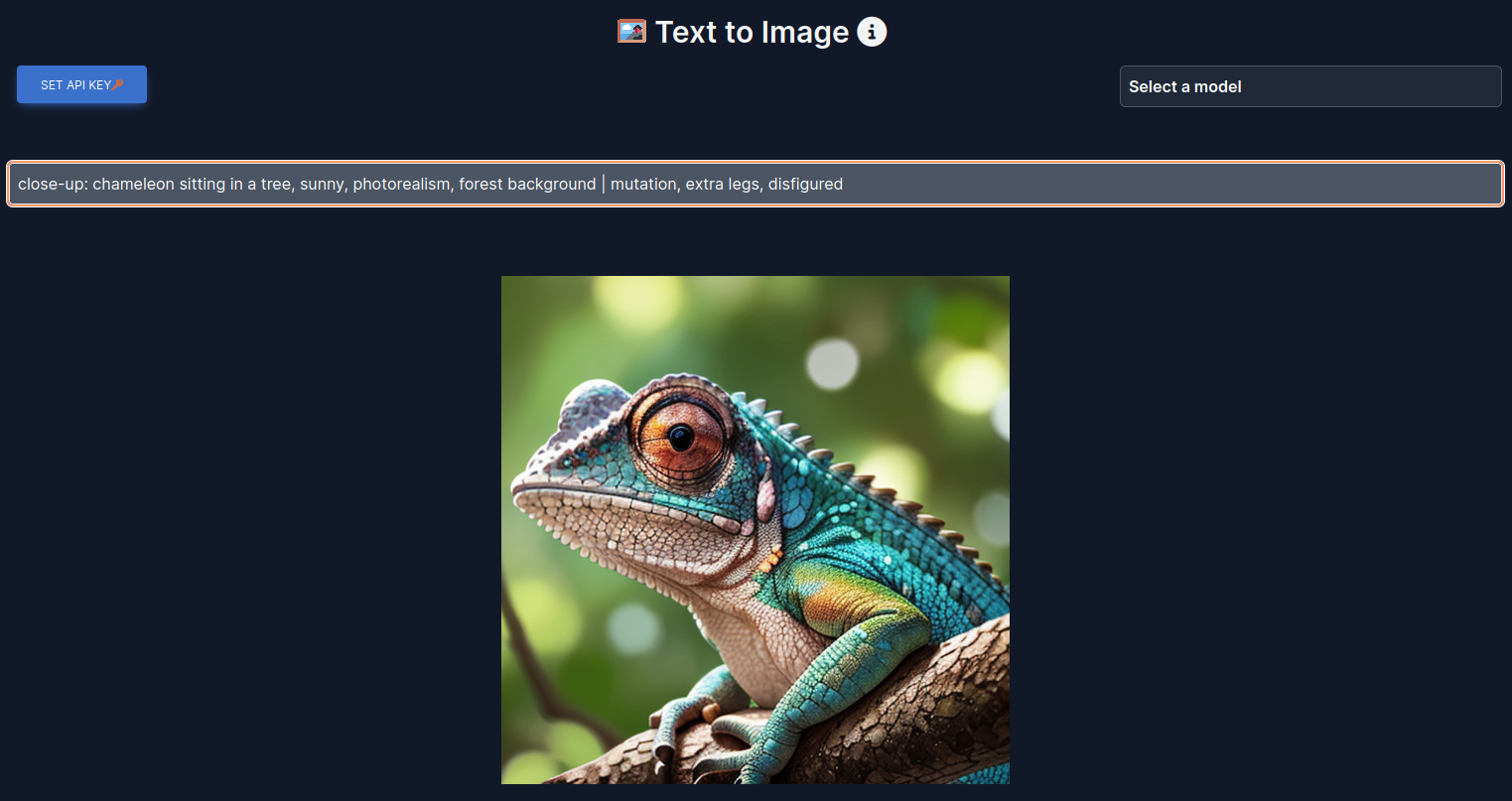
- Point your browser to the LocalAI WebUI at http://localhost:8080/ and click on Image Generation and select stablediffusion from the pull down menu on the right
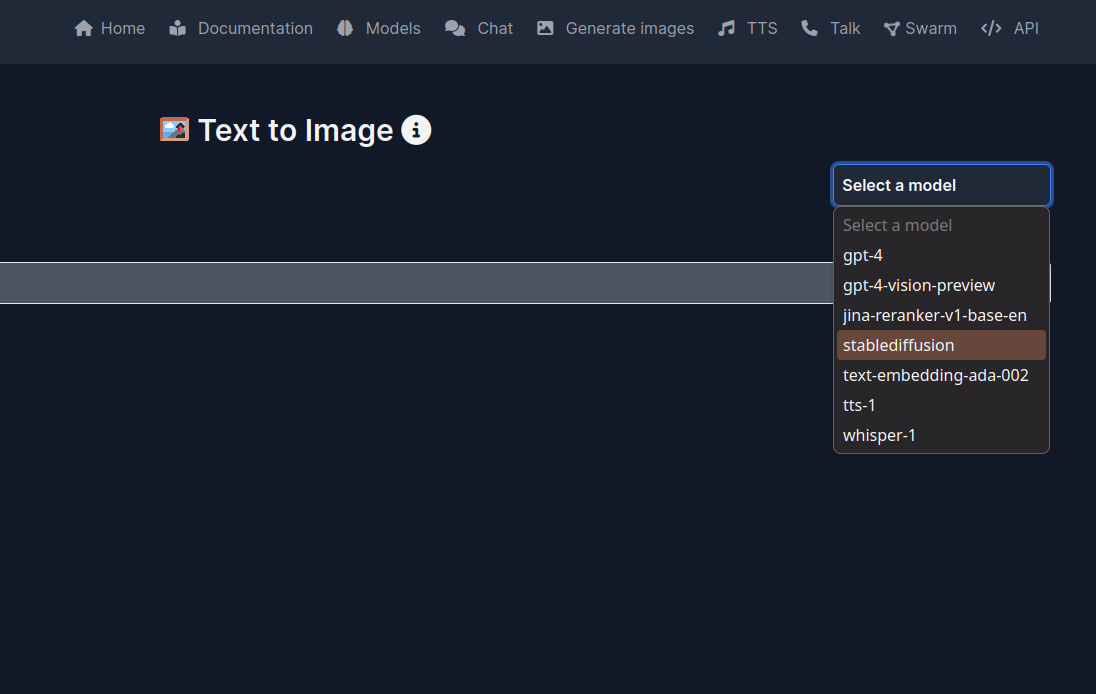
- Now enter a prompt to generate an image. Please note, that you can add a negative prompt separated by a “|“, containing criteria you don’t want in the image, e.g.
close-up: chameleon sitting in a tree, sunny, photorealism, forest background | mutation, extra legs, disfigured
- Watch the nvtop output, you should see a python compute process appear, and the memory and cpu usage increase, similar to this:
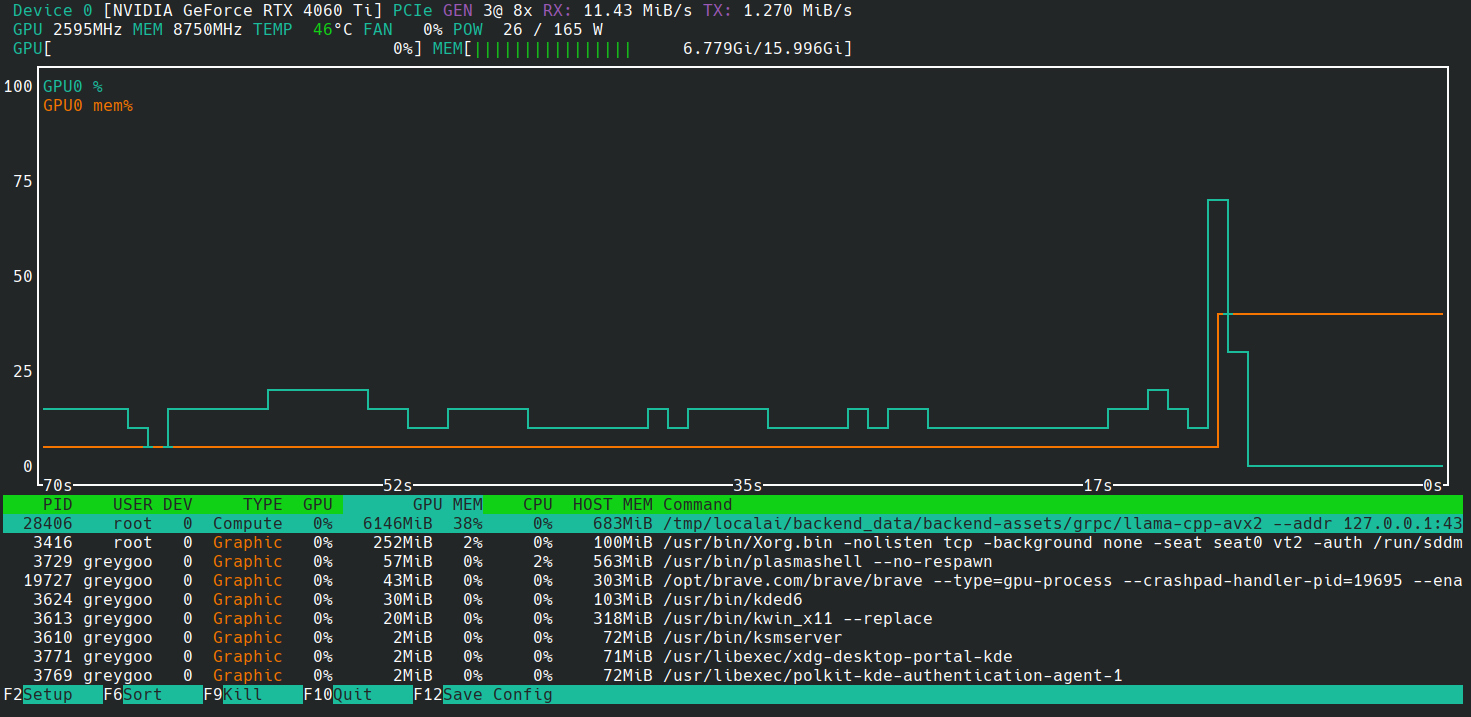
- After a short time, the generated image is shown in the browser.
With image generation, the result is highly dependent on exact descriptions of what is desired. As you have already seen, negative prompts can be used to avoid certain features, but there are e.g. also certain key words that can trigger a special style or certain other aspects. Some models require different prompt styles, reading the provided model documentation usually gives examples and a description. Writing good prompts has become its own skill that only can grow by experience. However some basic rules can be helpful to get more predictable results:
- Use concrete words. These are easier for the model to represent. This will give you more predictable results.
Examples: bus, ball, gecko, tractor, bicycle, seagull, spaghetti, pitchfork, tire, tomato, mousetrap, lantern, axe
- Avoid abstract words. With those the model will interpret more on what to generate and it’s harder to get the required result.
Examples: hope, progressive, adequate, sufficient, reality, intention, sympathy, point of view, absurd
- Select styles for the image to get overall changes. E.g.
Art styles: Abstract Expressionism, Anime, Artdeco, Bauhaus, Cubism, Cyberpunk, Dark Fantasy
Painting Types: Acrylic Paint, Airbrush, Graffiti, Oil on Canvas, Watercolor
Photography Styles: Fisheye Lens, Polaroid, , x-ray, infrared
- Use model specific trigger words to generate images using the specific training sets used. These are model specific and can be found in the model documentation.
Examples: pixel_art, line_art, comic, anime
- Use negative prompts. Most models support these and you can add them after the positive prompt, separated by “|”. They will cause the model to try to avoid what is described in them.
Examples: mutations, out of frame, blurry, missing legs, missing arms
You can find many more good examples and instructions for optimizing prompts on many sites dedicated to AI, check them out for more inspirations and ideas. Here some short prompts making use of the suggestions above:
close-up: Elegant Woman with golden crown, sweet expression, green eyes, black hair. background: rose garden, style: anime | crossed eyes, hands

bird’s eye view: magnificent victorian city in a light mist, beside the sea, sunset; style: photorealistic | birds, bend walls

mystical: straight forest stone trail, greenery, dense trees, dark, soft fog, night | bright, light

Beside using the image model that comes with the LocalAI All-in-One container images, there are a lot more Text-to-Image models available online, and you can add many of those to you LocalAI instance.
Please note, that these models come with licenses that need to be taken into account. For example, some models do not allow their use with a service that provides an API, like LocalAI does. Please make sure to first check if you are allowed to use a model, before installing it with LocalAI. Also be aware, that these models allow to create copyrighted content, that can cause legal consequences when published online.
Adding new models can’t be done in the WebUI, as there are not many configurations for those available in the LocalAI Gallery. You need to create your own configuration files for that, how this is done is shown with the following examples.
Add Models from Huggingface
huggingface is a site similar to github, that hosts all kind of generative models, datasets and other AI learning related resources from users to be downloaded or included directly in code. To add for example the image model OpenJourney:
- Go to the hugginface model page
- From the filters on the left, select Computer Vision: Text-to-Image
- In the Filter by Name field on top, enter a search term, e.g. openjourney
- Click on the model you would like to use
- Check on its Files and Versions tab, if it has a model_index.json file in the top directory
- Now copy the hugginface uri (prompthero/openjourney) on top of the model page and create models/openjourney.yaml pointing to it like this
(All model relevant changes to the defaults are in red):
name: OpenJourney parameters: model: prompthero/openjourney backend: diffusers step: 25 f16: true diffusers: pipeline_type: StableDiffusionPipeline cuda: true enable_parameters: "negative_prompt,num_inference_steps" scheduler_type: "k_dpmpp_2m" usage: | curl http://localhost:8080/v1/images/generations -H "Content-Type: application/json" -d '{ "prompt": "<positive prompt>|<negative prompt>", "step": 25, "size": "512x512", "model": "OpenJourney" }'
- Restart the LocalAI containers
- Go to Image Creation in the WebUI, and choose the now available OpenJourney from the pull down menu, and give it a prompt
close-up: chameleon sitting in a tree, sunny, photorealism, forest background | mutation, extra legs, disfigured
- When doing this for the first time, LocalAI will trigger the download of the model files, however as there is no output of its progress, you can watch the models/models–prompthero–openjourney folder size, that holds all related files.
- When all files have been download, the generated image is displayed.

This way you can add many Text-to-Image models from hugginface. Please note, that some models don’t provide a fp16 version, and will display an error message indicating this. In these cases the config entry
f16: false
needs to be set in the yaml file. For a full overview of possible config options and their meaning, please consult the LocalAI yaml documentation for all available options and the LocalAI Image Generation documentation on schedulers and backend parameters.
Add Models from Other Sources
Beside hugginface, there are a lot more models available on other sites, offered as single safetensor files. Civitai for example is a website that hosts primarily image generation models, but it is not possible to directly access them from LocalAI by providing a URI like for hugginface. The model files need to be downloaded manually and then referenced in a config file. To find and add models from Civitai:
- Go to Civitai and click on models
- Here search for the kind of model you are interested in, e.g. “pixel”
- In the results filter for
Model Type: Checkpoint - Now choose one of the available models, e.g. dreamshaper-pixelart
- Download the dreamshaperPixelart_v10.safetensors file from the model page and copy it to the models directory
- Now create a dreamshaperPixelart_v10.yaml config file like in the first example, but point directly to the downloaded model name:
name: dreamshaperPixelart_v10 parameters: model: dreamshaperPixelart_v10.safetensors backend: diffusers step: 25 f16: true diffusers: pipeline_type: StableDiffusionPipeline cuda: true enable_parameters: "negative_prompt,num_inference_steps" scheduler_type: "k_dpmpp_2m" usage: | curl http://localhost:8080/v1/images/generations -H "Content-Type: application/json" -d '{ "prompt": "<positive prompt>|<negative prompt>", "step": 25, "size": "512x512", "model": "dreamshaperPixelart_v10" }'
- Restart the LocalAI container
- Go to Image Creation in the WebUI, and choose dreamshaperPixelart_v10 from the pull down menu, and give it a prompt.
- Make sure to use the trigger words listed for the model on its model card on civitai. These words trigger the specific training sets and thus style or content used to train the model with. For the just added model this it either pixel_art or pixel_art_style:
pixel-art, close-up: chameleon in a tree, sunny, forest background | mutation, extra legs, disfigured
![]()
Using XL models
Up to now models trained with an image size of 512×512 were added, that only generated images of that resolution. To generate larger images, either use an upscale tool, or install XL models, that got trained on images with the size 1024×1024. However, in many cases, these models will not generate proper output when requesting images in lower resolution and you’ll get something like this:

If you get similar output for a model, you can’t use it through the WebUI, as here all request are made for a fixed size of 512×512. To generate images with different resolutions, you will have to directly contact the LocalAI API with e.g. a curl request. One of the more popular models you can use, and base for many others is Stable-Diffusion-XL-1.0, also often abbreviated as SDXL1.0 or simply SDXL:
- Create models/Stable-Diffusion-XL-1.0.yaml and paste the following config
name: Stable-Diffusion-XL-1.0
parameters:
model: stabilityai/stable-diffusion-xl-base-1.0
backend: diffusers
f16: true
cuda: true
threads: 7
step: 25
debug: true
gpu_layers: 10
diffusers:
scheduler_type: k_dpm_2_a
cuda: true
usage: |
curl http://localhost:8080/v1/images/generations
-H "Content-Type: application/json"
-d '{
"prompt": "<positive prompt>|<negative prompt>",
"model": "Stable-Diffusion-XL-1.0",
"step": 25,
"size": "1024x1024"
}
- Create a shell script txt2img_sdxl.sh with the curl request:
#!/bin/sh
positive_prompt="${1:-"pixel-art, close-up: chameleon in a tree, sunny, forest background | mutation, extra legs, disfigured"}"
negative_prompt="${2:-"mutation, extra legs, disfigured"}"
curl http://localhost:8080/v1/images/generations
-H "Content-Type: application/json"
-d '{
"prompt": "'"$positive_prompt"'|'"$negative_prompt"'",
"model": "Stable-Diffusion-XL-1.0",
"step": 25,
"size": "1024x1024"
}'
- Now you can run the script, and pass the positive and negative prompt as parameters
./txt2img_sdxl.sh "close-up: cameleon; creative, modern, digital, color explosion, vibrant shades; style: expressionism" "mutation, disfigured, letters, numbers"
- LocalAI returns a url to the generated image
{“created”:1727819277,”id”:”d1a755c7-0dcc-45f6-84e4-23a79c41456e”,”data”:[{“embedding”:null,”index”:0,”url”:”http://127.0.0.1:8080/generated-images/b643021618459.png”}],”usage”:{“prompt_tokens”:0,”completion_tokens”:0,”total_tokens”:0}}

As you have seen, adding and using image generation models with LocalAI is easy and fun. Since AI image generation has become a huge field, only a small portion of what is possible can be covered in this post. Further functionality like Image-to-Image or Depth-to-Image generation as well as the usage of low-rank adaption (Lora) models or the combination of several models to form AGI (artificial general intelligence) functionality will be covered in coming posts. Happy Hacking!
(Visited 1 times, 1 visits today)