
Reimagining the Fedora Linux installer: Anaconda’s new Web UI
The Fedora Linux installer, Anaconda, has been around for 25 years!
While it’s been a reliable way to install Fedora Linux (and CentOS, RHEL, and others), many people — especially those new to Fedora — sometimes have issues with complexity and jargon.
We’re working on a major update for the way it looks and acts. Our new interface is designed to make installing Fedora Linux simpler and more user-friendly for everyone, especially newcomers.
Skip to the download instructions to try it out or read on to learn about the background of the changes and to see screenshots.
Why a new interface?
The Anaconda team implemented the current design of the GTK-based installer decades ago. It uses a “hub-and-spoke” design that can sometimes feel like jumping around sections when installing.
We wanted to rethink the installation process, to create a more streamlined experience where people are guided through the installation process step-by-step in a linear manner, so they don’t have to hunt for the right things to configure amid all the possible settings.
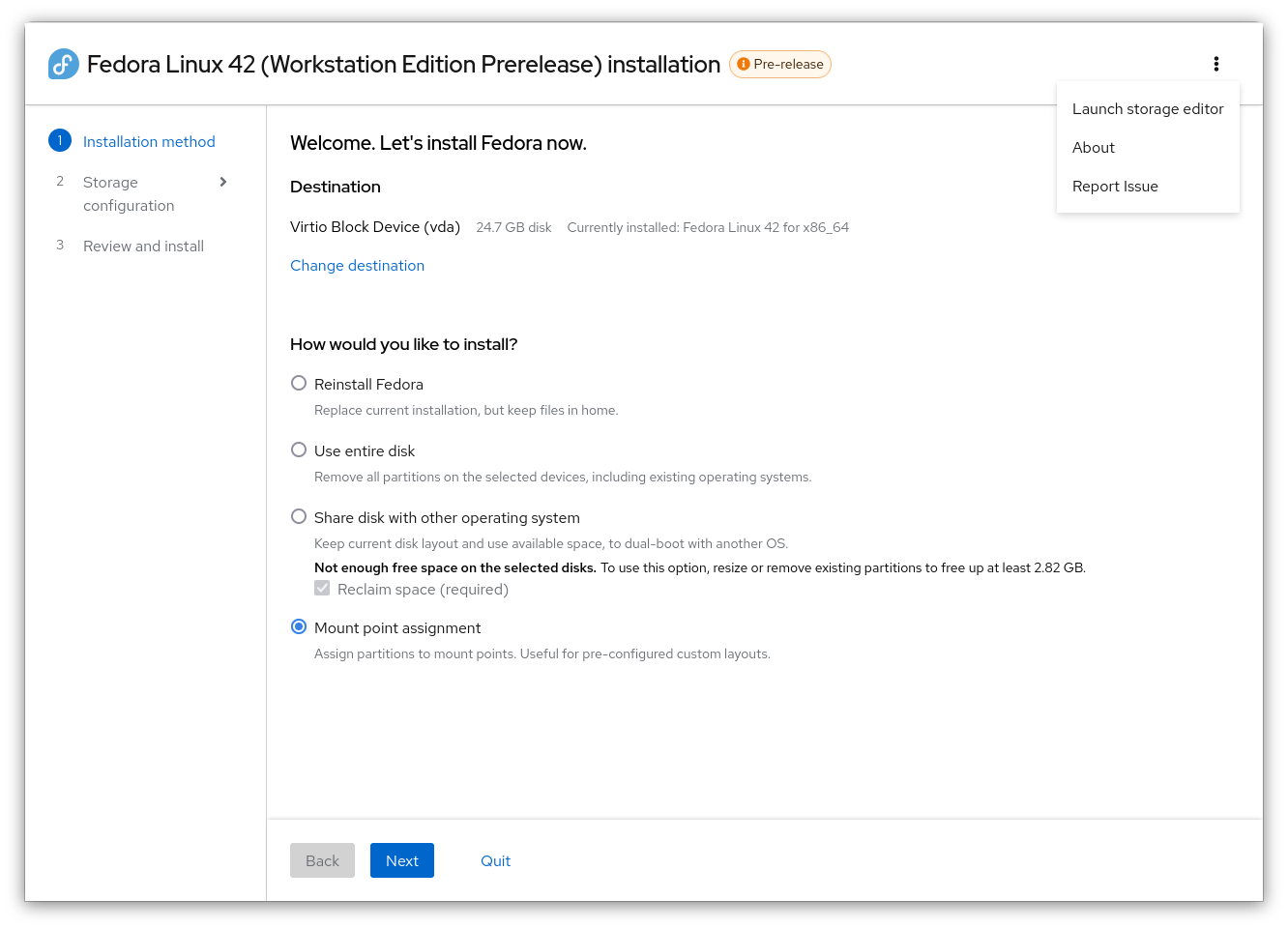
Instead of figuring out how to configure the system first, the goal should be to show you a set of applicable options, and then tailor the experience from there. The new interface was designed to be a “guided” experience with good defaults to help people install in different ways, right from the start. It lists possible options on how to install, instead of the longstanding method which requires dealing with technical details of the system to install.
Most typical installations should require not much more than clicking “next” a couple times, have a review page, and then installation. This will make installation not just easier for newcomers to Fedora, but also more streamlined for all of us who have used Fedora Linux for decades.
A task-oriented design
During the start of the project to re-imagine Anaconda, we identified a few different goals people have when they install Linux on their computer:
- Use the entire disk for a fresh installation: Useful for new computers, new disks, or to wipe out an existing install to start fresh.
- Share disk with another operating system in a dual-boot mode: Share the computer between OSes (Windows, macOS, or even another Linux distribution), in a dual-boot fashion. Fedora will be installed to free space. If there is no free space, a “reclaim” dialog can remove partitions or resize (when partition type supports resizing) to make space. Having dual booting explicitly stated is new to Anaconda, even though it has previously supported this.
- Reinstall Fedora (new to Web UI): Use Anaconda to re-install Fedora when there’s a problem, keeping your data with a new installation. This is a “system recovery” option, new to Anaconda.
- Custom partitions, using mount point assignment: Install on a pre-configured disk, either set up from a partition tool (for example: using the Cockpit Storage powered “Storage Editor” or a fully external tool such as gparted) ahead of time or re-use existing partitions from a previous installation (such as switching from another Linux distribution).
{kind=link}
The new Web UI is designed to handle all these scenarios easily. Previously, Anaconda required some technical know-how, especially for custom installations. Now, even people unfamiliar with disk partitioning should be able to easily install Fedora, without having to refer to third-party guides or scratching their heads trying to figure out how to partition a disk.
Additionally, we’re adding more to Anaconda too: The older GTK-based Anaconda does not have an easy way to do a “recovery” reinstall which preserves data in home directories. And dual-booting with the GTK version of Anaconda is currently a bit difficult; the new Web UI version of Anaconda makes this much easier.
We’ll talk more about each method further down the page, complete with screenshots!
Changing the Anaconda experience
Anaconda has always used GTK, the “toolkit” that provides the buttons and other widgets that make up many applications and desktops on Linux. The last refresh happened over a decade ago (2013, in Fedora 18). For most of this time, Anaconda’s interface (the part of Anaconda that you see) has been tightly coupled with the backend logic. A few years ago, the Anaconda team started a major effort to modularize Anaconda, to break the code down to smaller parts, which enabled the interface to be changed independently from installation logic.
GTK 3 is still currently maintained, but it’s old and showing its age. It won’t be maintained forever. Porting to GTK 4 (and possibly GNOME’s special widget set, libadwaita) will require a lot of effort to adapt to the changes and would require a massive effort to rewrite much of the frontend, especially as Anaconda has many custom GTK widgets.
Since we’d likely have to rewrite a lot of the frontend anyway, we took another approach and have taken advantage of the modularization efforts to retool the frontend to have a web-based interface instead. The Cockpit team has been providing a web-based interface for Linux systems for managing systems for many years in the Cockpit web console, so it made sense to reuse Cockpit as a base and its web-based widget set, PatternFly, as a starting point for the next generation of Anaconda too.
By-the-way: We’re using Firefox to render the UI when you’re installing locally. (There’s no Chromium or Electron involved.)
Web-based benefits
While it’s not a native toolkit like GTK, using a web based UI does have several benefits:
- It’s easier to update and maintain versus a traditional desktop application
- We now use Cockpit’s testing frameworks to test Anaconda’s web UI
- It’s easier to adapt to future changes
- It enables more community contributions, as it “lowers the bar” for know-how, as there are many more developers familiar with web development than GTK development
- We can extend it to interactively install a remote machine using Anaconda from another computer’s Web browser in the future
Room to grow
We have some plans to expand the storage configuration screen, to provide more than just encryption. For example, in the future we could:
- Add support for remote installations by browser. No complicated tools or connection configuration would be required.
- Extend small-screen support needed for VMs to have possible mobile support for remote installations. PatternFly and Cockpit both help provide some of the underpinnings to enable this work.
- Have settings to use a different filesystem configuration, such as XFS and ext4, and a way to switch between subvolumes, logical volumes, and Stratis layouts.
We’re also planning on adding:
- A built-in terminal for debugging purposes
- An integrated log viewer
- Improved light and dark mode switching
- Improved accessibility
Details about the new storage concepts
The GTK version of Anaconda currently shows you a disk and you need to figure out what to do with it in order to install a system.
The new web UI version of Anaconda uses more of a top-down approach, where you decide how you’ll install on a system, based on the current system’s available storage.
While we already covered it above in a list, let’s dive more into details here, as this does change the way you interact with Anaconda quite a bit, as these are newer concepts when installing Fedora.
The most simplified method is to use the entire disk. This is perfect if you have a blank disk you’d like to install on, either on physical hardware or in a VM. It’s also a great choice if you don’t care about what’s currently on the disk and want to easily install Fedora.

Sharing a disk with another operating system makes it easy to install Fedora along side another operating system. It has a reclaim dialog to erase partitions or even resize supported partitions. If your partition is formatted in a filesystem type that is not supported, you’ll have to either delete partitions in the reclaim dialog or use an alternate tool, like GParted, before launching Anaconda. Windows installations are now encrypted by default with “BitLocker”, so if you’d like to share your computer’s hardware between Windows and Fedora Linux, you will first need to boot into Windows and resize partitions from within Windows itself to make space for Fedora.

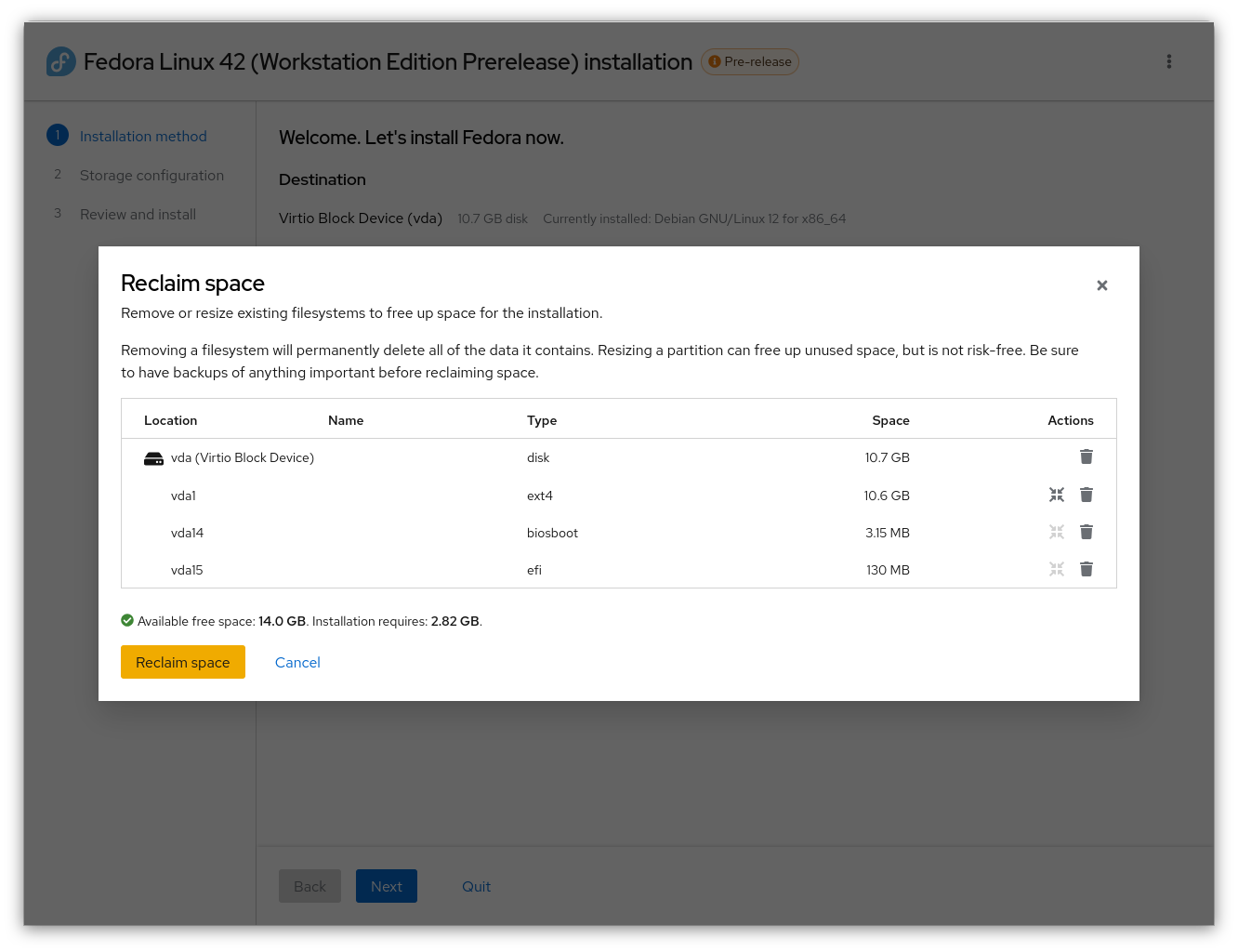
If none of the above methods work for you, you’re able to select a flexible layout based on an existing layout on your disk. Linux systems have standard places to add storage called mounts. When using the mount point method, you can select partitions for each mount point, starting with the mandatory “root” partition at “/”, and continuing with the suggested “/boot/” mount point. Additional mount points can be added and assigned existing partitions as well, using free-form text for the names.
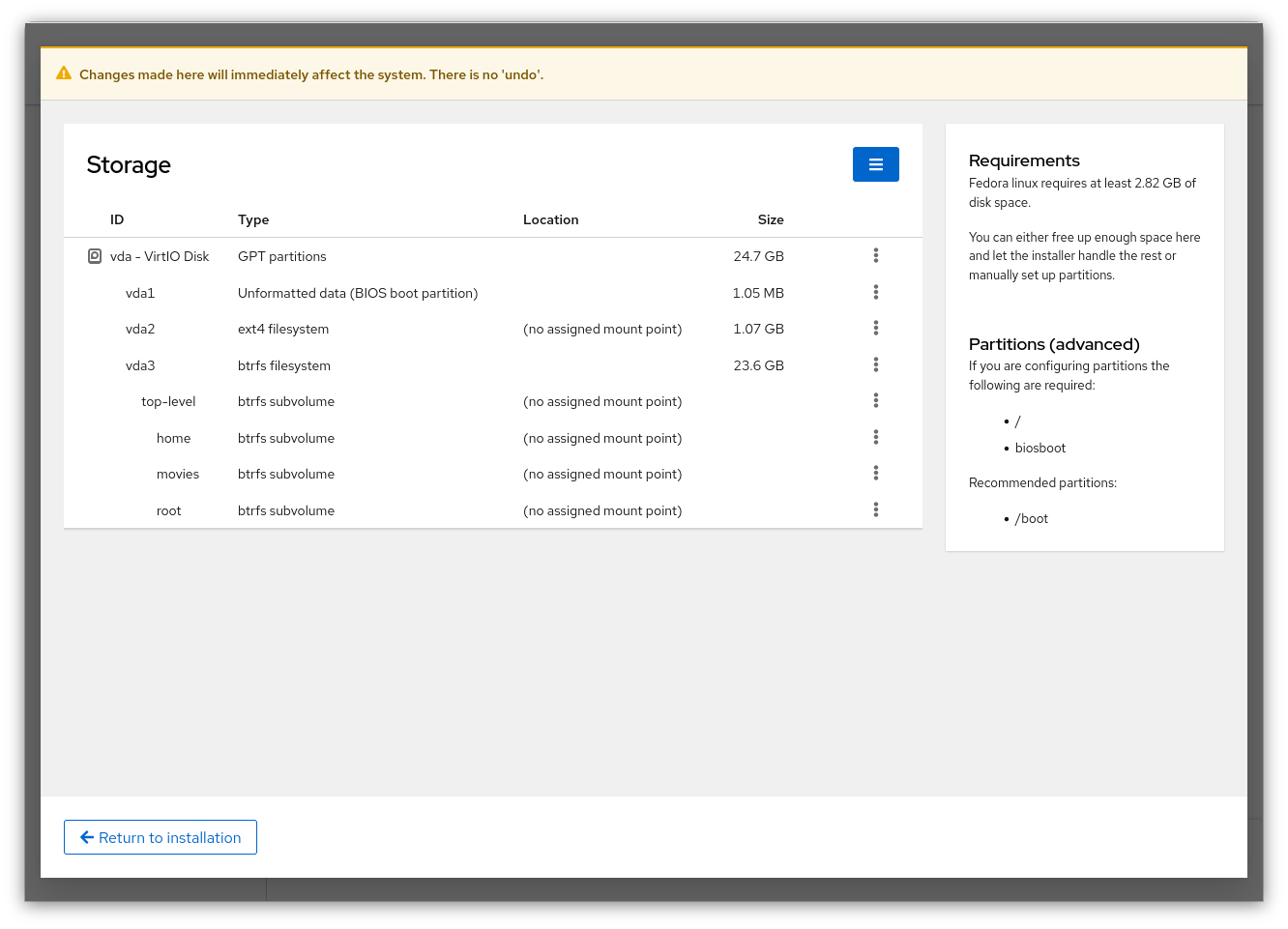
If your storage is not set up how you’d like it on the disk and if you don’t want to use one of the guided partition methods, then you can either use an external tool before installing Anaconda to set up partitions and volumes how you’d like, or you can use the “Storage Editor” from Anaconda’s top-right “global” menu on the storage page. This will launch a customized version of “Cockpit Storage” to let you adjust your storage on the fly, to prepare it for Anaconda. Please note, as pointed out in the warning dialog, that this acts directly on your system, unlike Anaconda itself, which queues everything up until you agree on the review screen.


And, if you already have Fedora installed and want to reinstall for any reason, existing Fedora installations have a “reinstall method” at the top. This lets you do a fresh installation and keep all the data in your home partition, instead of having to erase everything.

Screencast demos
We’ve also put together a few screencasts to show you what it would be like to use Anaconda.
Ready to try it out?
We have a test ISO you can try out! We’d love to hear from you! Try this out on a secondary machine or in a virtual machine. Do not install this on your main computer or any machine with important information.
To try out the new Web UI installer, you can set up the test ISO on either a virtual machine or real hardware. Here’s how to do each.
Virtual machine:
- Download the ISO
- Open your virtual machine software, such as GNOME Boxes
- Select the ISO
- Boot your virtual machine
Physical test hardware:
- Download the ISO
- Download Fedora Media Writer (or use another USB stick imaging tool)
- Launch Fedora Media Writer and select the downloaded test ISO
- Insert the USB stick you’d like to overwrite with the installer
- Write the ISO to the USB stick (this will take a few minutes)
- Boot your test computer with the USB stick in a USB slot
- Press a key to select your boot device. This is often the <F12> or <ESC> or <Del> key, depending on manufacturer.
- Start your installation!
A few notes about the test image
While new Anaconda Web UI is almost ready for its debut in Fedora Linux 42, starting with the Workstation Live ISO, there are a few things to keep in mind:
- This is the Workstation live image with the GNOME desktop.
- This current demo is English only. Translations are in progress. There will be a language selector in release versions. Don’t worry; we have it implemented and it works, but it’s not ready for testing yet, and actual translations are being worked on too.
- We’re still refining the text used in the installer, so words may change a little still. If something is unclear to you, we’d like to solve it.
- We’re planning a staged rollout, first changing the Workstation installation experience, then extending Anaconda to handle other desktop installations too. After that, we will adapt it to server installations as well. So even if you do not use GNOME, testing out this ISO and providing feedback will help improve Anaconda for other uses in the future.
We’re hoping to incorporate more feedback from people trying this out, so please let us know any constructive and helpful feedback you might have! Be sure to try it out in different scenarios.
Contact us
We’re currently doing a “Test Week” (a week of “Test Days”) for the new Anaconda Web UI this week, from November 11 – 15. Read more on the blog post about the Anaconda Web UI Test Week and the detail of how Test Days work.
We’re looking forward to hearing all positive and/or constructive feedback. The forum post for the test week is a great place for you to share a comment! Thanks!
If you find a problem, report a bug at Bugzilla.