
Introduction to AI training with openSUSE
In my last posts I explained on how to run AI models on a openSUSE system using LocalAI. Now I’d like to introduce you to training AI with a small guide on creating a Low Ranking Adaption, also known as LoRA, and using it with LocalAI on your system. This way, you can leverage AI functionality using your local data without worrying about exposing it to external parties.
Previous posts in this series:
Generating images with LocalAI using a GPU
Training AI has become a wide field, and to start off with that, I’m going to create a LoRA (Low Ranking Adaption) for an existing image model, in this example StableDiffusionXL1.0
What is a LoRA
LoRA stands for Low Ranking Adaption and is a technique for quickly adapting existing models to new contexts. This adaption makes huge and complicated machine learning models much more suited for specific uses by adding lightweight pieces to the original model, instead of changing the entire model. Getting a model to work in specific contexts can require a great deal of retraining, which is expensive and time-consuming. LoRA provides a quick way to adapt the model without retraining it. Typical use cases for LoRAs are specific styles/themes like wintery or halloween LoRAs, specific persons, animals or simple a company logo that should be added. In this post, I’ll go through creating a LoRA for image generating models, but LoRAs exist for other models like language generating ones as well.
Requirements
The training itself is not done with LocalAI, but an extra tool called Kohya’s GUI that provides a nice web interface to configure and manage training data. The requirements for LoRA training are about the same as for running the model, so GPU support is highly recommended. I’ll use the docker container based deployment, for a description of the requirements and on how to setup a openSUSE system for GPU support in docker, please read my previous blog post.
System preparation
All required here, is to run Kohya’s GUI as docker container in a location with at least 50G free disc space:
git clone --recursive https://github.com/bmaltais/kohya_ss.git cd kohya_ss docker compose up -d --build
All training data and the resulting LoRA reside in the kohya_ss/dataset directory, which is mounted as /dataset inside the container. Once the container is running, the Kohya web interface is available at http://localhost:7860/ and a TensorBoard UI at http://localhost:6006/. For training only the Kohya interface is required.
Training Data
Since the post will cover only the technical aspects, I’m just using images for a data set that will be easy to be tested against later. For that, I chose Kryton, a robot with an recognizable head from a British TV show.
Please note, that you can use images from the internet for training, but if you are planning to release your trained model, you might first want to check with the rights owner to avoid legal trouble. I’m using these images only for demonstration purposes and the resulting model will not be released or made in any way publicly available.
Select images
The most important aspect to consider when selecting images for training, is that the model will pick up all recurring elements in them. If you use for examples several pictures with e.g. a black border, then the resulting LoRA will also generate black borders in images. The same is true for aspects like low grain photographs, uneven lightning or simply images with identical background. Please consult dedicated tutorials on image selection and preparation for more information as I won’t go in depth into all additional aspects of image selection and preparation.
A good number of images to start with is around 10 – 20. Here the selection used for demonstration, these images are in no way optimal, but will be enough to train a working LoRA.
Caption images
- Copy the images to a own folder at kohya_ss/dataset/images/<dirname>
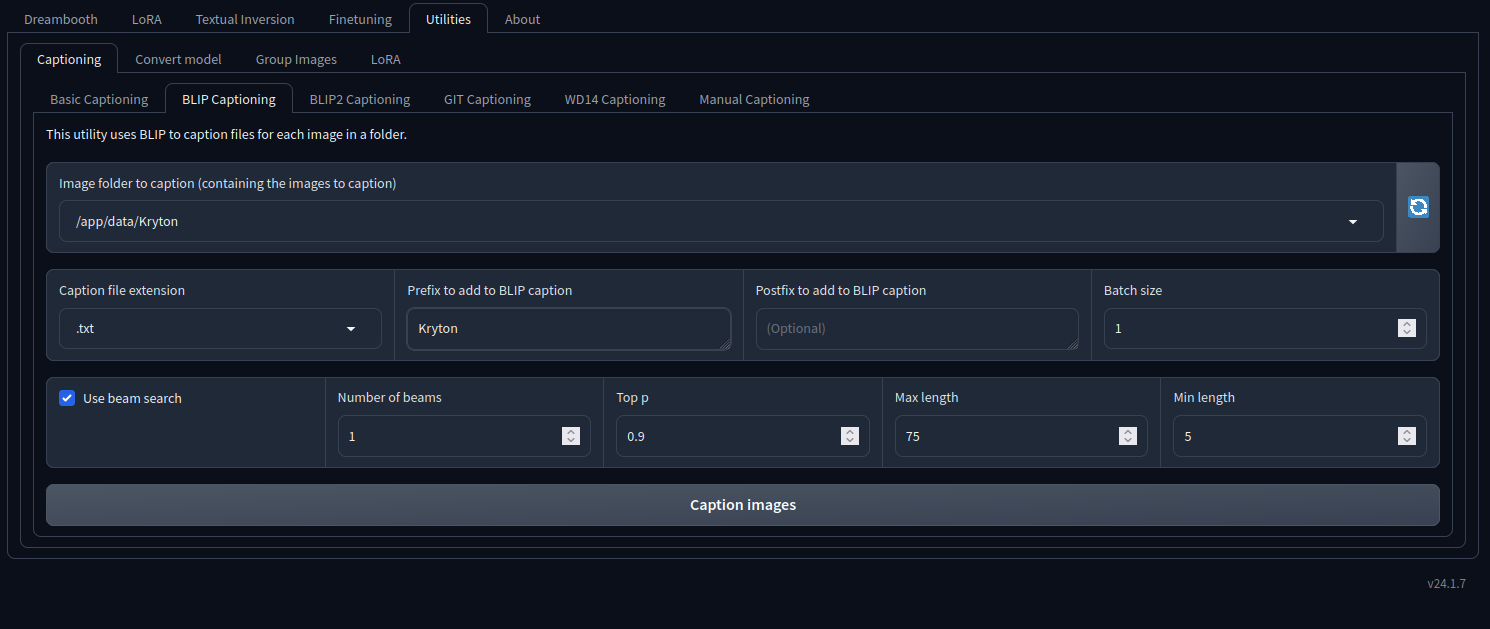
- In the Kohya web interface at http://localhost:7860 click on Utilities->Captioning->BLIP Captioning
- Select the directory containing the images
- Add a Prefix to add to BLIP Caption
- Click “Caption”
Dataset Preparation
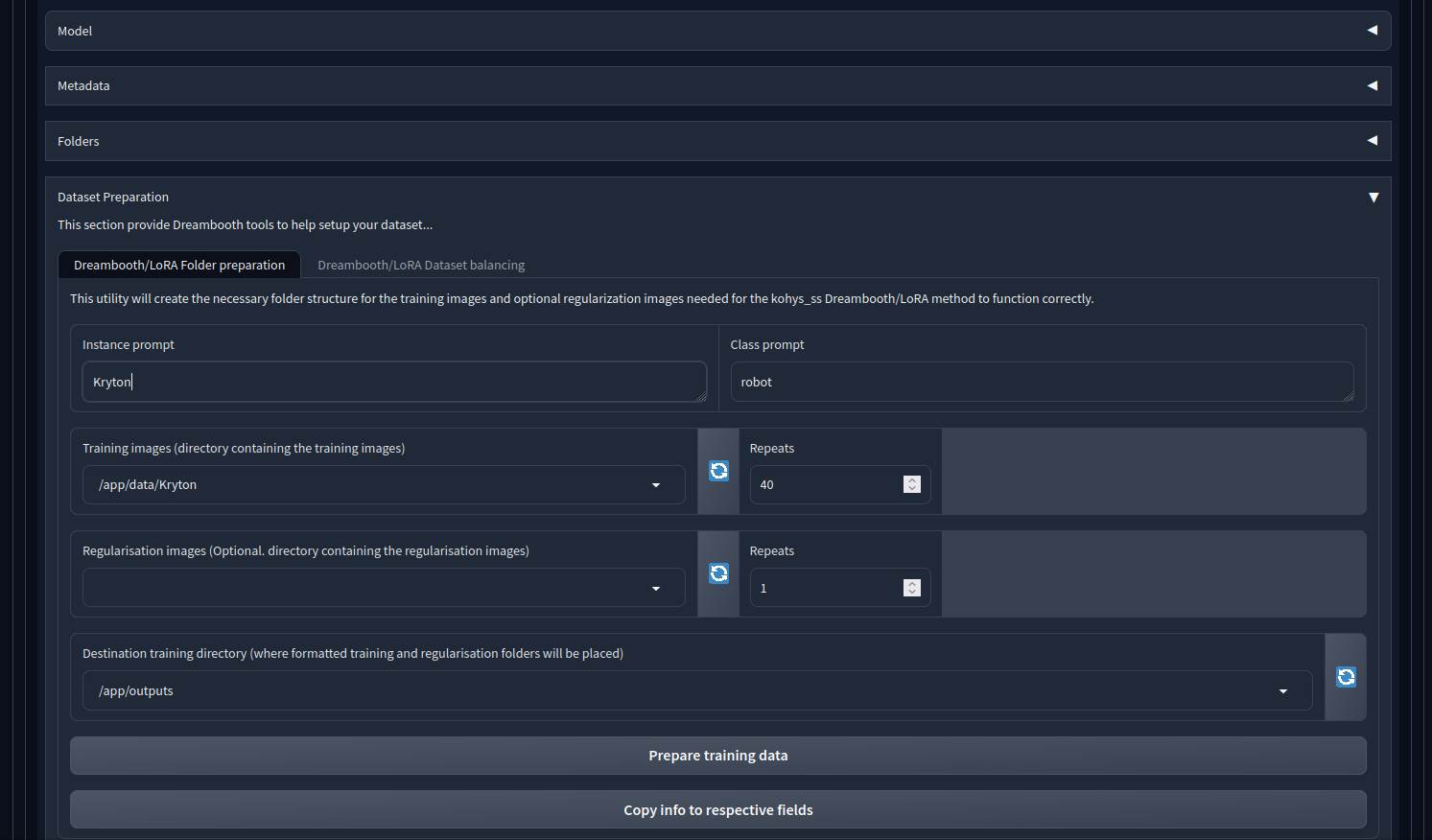
- Go to LoRA->Training->Data Set Preparation
- Enter an instance prompt, the key word in a prompt that will cause the use of the LoRA
- Enter a class prompt
- Select the directory containing the training images
- Select the destination training directory
- Click on Prepare Training Set
Select Model
- Go to LoRA->Training->Model
- Select the base model the LoRA should be trained for
- Select the folder containing the training images
- Enter a Trained Model output name

Folders
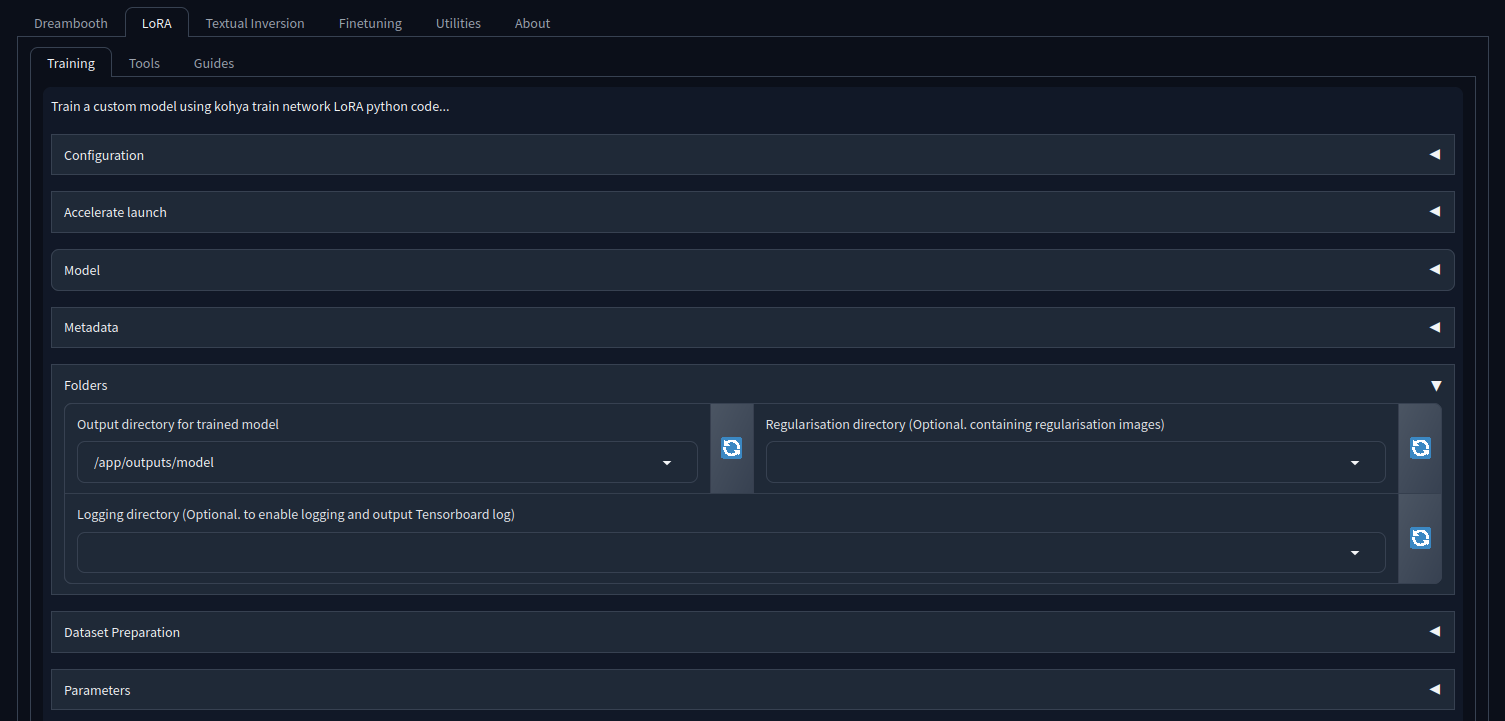
- Go to LoRA->Training->Folders
- Set the Output directory for trained model
Parameters
For the first run, I’ll leave everything on its default values. However, since my base model is StableDiffusion-1.0, I need to enable the No halfVAE option in order to not run into an error while training:

Training
Once all the above steps are done, I can click the Start Training button on the bottom of the page, and watch the training process in the terminal I started the docker image in. After about 10-15 minutes, the training should be done, and a file called kryton.safetensors appears in the dataset/outputs/model folder. This is the LoRA I just created, and that I now can use with LocalAI for image generation.
Adding the model to LocalAI is straight forward and only needs a small modification of the SDXL1.0 config file. If you want to know how to set up LocalAI and generate images with it, please read my dedicated blog post on that. For a detailed explanation of LocalAI and its directory structure, please log at how to run AI locally.
Creating a LoRA configuration
- In the LocalAI environment, create models/stabilityai/loras/
Please note that stabilityai is derived from the model entry
model: stabilityai/stable-diffusion-xl-base-1.0
- Copy the model file to models/stabilityai/loras/
- Copy the existing models/Stable-Diffusion-XL-1.0.yaml configuration file to Kryton.yaml or create it from scratch
- Insert the lines
lora_adapter: "loras/kryton.safetensors" lora_base: "stable-diffusion-xl-base-1.0" lora_scale: 0.5
- Change the name of the configuration
- The final config file should look like this (changed/new element are red)
name: lora-kryton parameters: model: stabilityai/stable-diffusion-xl-base-1.0 lora_adapter: "loras/kryton.safetensors" lora_base: "stable-diffusion-xl-base-1.0" lora_scale: 0.5 backend: diffusers f16: true cuda: true threads: 7 step: 25 debug: true gpu_layers: 10 diffusers: scheduler_type: k_dpm_2_a cuda: true usage: | curl http://localhost:8080/v1/images/generations -H "Content-Type: application/json" -d '{ "prompt": "<positive prompt>|<negative prompt>", "model": "txt2img_stable-diffusion-xl-base-1.0", "step": 51, "size": "1024x1024" }'
- Restart the LocalAI containers
Create images
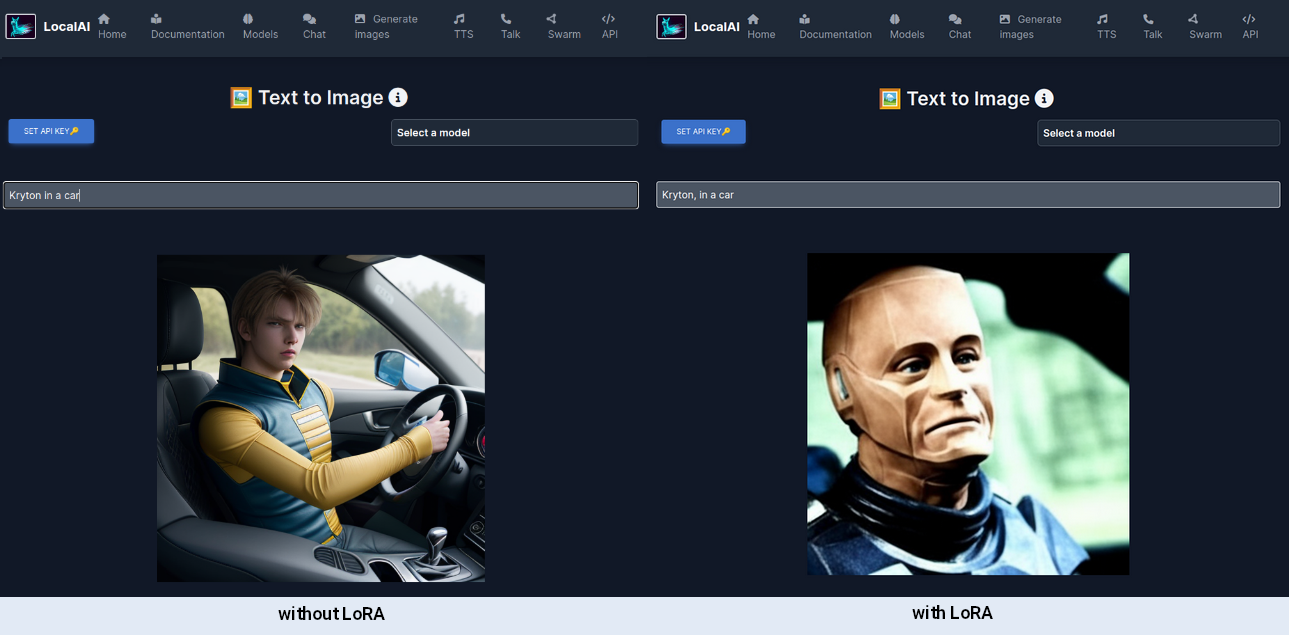
Once LocalAI is up and running again, I’ll go to its web interface, select create images and choose lora-kryton from the model list, enter a prompt containing the instance prompt that was set earlier, in my case Kryton, and hit enter. For comparison here images generated without and with the LoRA:
Creating LoRAs for existing image generation models is not hard. From here on, you can now play with parameters, improve the images selection and create better captions. Ready to use LoRAs can be downloaded from e.g. CivitAI, where some users also share their training sets with them. A list with good examples can be found here.
Have a lot of fun with AI under your own control!
(Visited 1 times, 1 visits today)