I Ran 9 Popular LLMs on Raspberry Pi 5; Here’s What I Found
Just to give you a quick refresher, the Pi 5 is a tiny computer with a 4-core Cortex-A76 CPU, up to 8GB of RAM, and a VideoCore VI GPU. It’s basically a pocket-sized computer.
Now, the real fun begins. Our contenders for this experiment include a diverse range of LLMs, each with its own strengths and limitations. We’ll be testing Phi-3.5B, Gemma2-2B, Qwen2.5-3B, Mistral-7B, and Llama 2-7B.
Let’s see which of these language models can rise to the challenge of running on a Raspberry Pi 5.
Testing Criteria
To ensure a fair and objective evaluation of the LLMs, I used a standardized approach with every model.
I tested all the models directly in Ollama within the terminal, without a GUI, to remove any overhead in performance and provide a bare-metal approach to see how these models will perform.
Task: Each LLM had a task to generate a Docker Compose file for a WordPress installation with a MySQL database.
Metrics:
- Inference time: The time elapsed from the prompt being issued to the completion of the Docker Compose file generation. A shorter inference time indicates better performance.
- Accuracy: The correctness and completeness of the generated Docker Compose file. We will assess whether the file accurately defines the necessary services, networks, and volumes for a functional WordPress installation.
- Efficiency: The resource utilization of the LLM during the task. We will monitor CPU usage, memory consumption, and disk I/O to identify any performance bottlenecks.
Google’s Gemma 2 model is offered in three sizes 2B, 9B, and 27B each with a new architecture that aims to deliver impressive performance and efficiency.
As you can see in the video above, the performance of Google’s Gemma2 model on the Raspberry Pi 5 was impressive.
The inference time was fast, and the response quality was excellent while utilizing only 3 GB of RAM out of the available 8 GB, leaving plenty of headroom for other tasks.
Given these results, I would rate this setup a solid 5 out of 5 stars.
Qwen2.5 is the newest generation in the Qwen series of large language models. It includes various base models and instruction-tuned versions, available in sizes from 0.5 to 72 billion parameters. Qwen2.5 brings several enhancements compared to its predecessor, Qwen2.
It is my first time testing this model and I was highly impressed by it. The inference time was remarkably fast, and the responses were accurate and relevant.
It utilized 5.4 GB of RAM out of the available 8 GB, leaving some headroom for other tasks.
This means you can easily use Qwen2.5 while juggling other personal activities without any noticeable slowdowns.
Phi-3.5-mini is a compact, cutting-edge open model derived from the Phi-3 family.
It is trained on the same datasets, which include synthetic data and curated public websites, emphasizing high-quality, reasoning-rich information.
With a context length of 128K tokens, this model has been refined through a comprehensive process that combines supervised fine-tuning, proximal policy optimization, and direct preference optimization to enhance its ability to follow instructions accurately and maintain strong safety protocols.
In my test of Microsoft’s Phi 3.5 model, the performance was somewhat okayish.
While the inference time wasn’t too shabby and the responses initially seemed good, the model started to hallucinate and produce inaccurate outputs.
I had to forcefully quit it after about 11 minutes, as it showed no signs of stopping and would likely have continued indefinitely.
The model utilized around 5 GB of RAM, which left some capacity for other tasks, but the hallucinations ultimately detracted from the overall experience.
Mistral is a 7-billion-parameter model released under the Apache license, offered in both instruction-following and text completion variants.
According to the Mistral AI team, Mistral 7B surpasses Llama2- 13B across all benchmarks and even outperforms Llama 1 34B in several areas.
It also delivers performance close to CodeLlama 7B for coding tasks, while still excelling in general English language tasks.
I was skeptical about this model since it was a 7b parameter model but during my testing on Pi 5, it did manage to complete the given tasks, although the inference time wasn’t super speedy around 6 minutes.
It utilized only 5 GB of RAM, which is impressive given its size, and the responses were correct and aligned with my expectations.
While I wouldn’t rely on this model for daily use on the Pi, it’s definitely nice to have as an option for more complex tasks when needed.
Llama 2, developed by Meta Platforms, Inc., is trained on a dataset of 2 trillion tokens and natively supports a context length of 4,096 tokens.
The Llama 2 Chat models are specifically optimized for conversational use, fine-tuned with more than 1 million human annotations to enhance their chat capabilities.
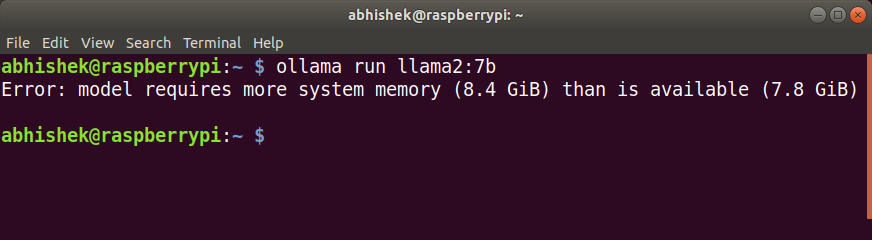
Well well well, as you can see above in my attempt to run the Llama 2 model, I found that it simply didn’t work due to its higher RAM requirements.
Code Llama, based on Llama 2, is a model created to assist with code generation and discussion.
It aims to streamline development workflows and simplify the coding learning process.
Capable of producing both code and explanatory natural language, Code Llama supports a wide range of popular programming languages, such as Python, C++, Java, PHP, Typescript (Javascript), C#, Bash, and others.
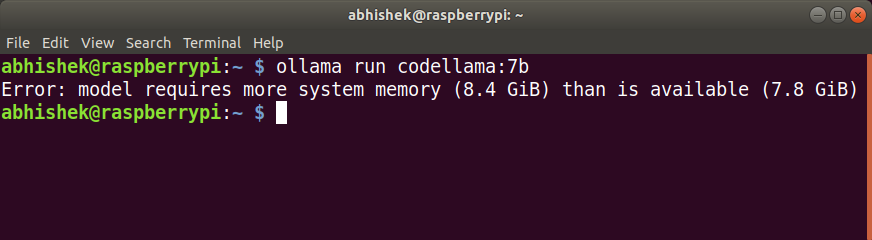
Similar to llama2 model, due to its higher RAM requirements, it didn’t run at all on my Raspberry Pi 5.
Nemotron-Mini-4B-Instruct is designed to generate responses for roleplaying, retrieval-augmented generation (RAG), and function calling.
It’s a small language model (SLM) that has been refined for speed and on-device deployment using distillation, pruning, and quantization techniques.
Optimized specifically for roleplay, RAG-based QA, and function calling in English, this instruct model supports a context length of 4,096 tokens and is ready for commercial applications.
During my testing of Nemotron-Mini-4B-Instruct, I found the model to be quite efficient.
It managed to deliver responses quickly, with an inference time of under 2 minutes, while using just 4 GB of RAM.
This level of performance makes it a viable option for your personal co-pilot on Pi.
Orca Mini is a series of models based on Llama and Llama 2, trained using the Orca Style datasets as outlined in the paper “Orca: Progressive Learning from Complex Explanation Traces of GPT-4.”
There are two versions: the original Orca Mini, which is built on Llama and comes in 3, 7, and 13 billion parameter sizes, and version 3, based on Llama 2, available in 7, 13, and 70 billion parameter sizes.
Orca Mini utilized 4.5 GB of RAM out of the available 8 GB, and the inference time was good.
While I’m not entirely sure about the accuracy of the responses, which will need to be verified by testing the output file, I would still recommend this model for its efficiency and performance.
CodeGemma is a versatile set of lightweight models capable of handling a range of coding tasks, including fill-in-the-middle code completion, code generation, natural language understanding, mathematical reasoning, and following instructions.
My experience with CodeGemma was quite interesting. Instead of responding to any of my queries, the model amusingly began asking me questions, almost as if it had a personality of its own.
I believe this behavior might be due to its focus on code completion, so I plan to test it in an IDE to see how it performs in that context.
Despite the unexpected interactions, it successfully loaded up in Ollama and used only 2.5 GB of RAM, which is impressive for such a lightweight model.
My Ratings
Please note that all the ratings provided are subjective and based on my personal experience testing these models.
They reflect how each model performed for me on the Raspberry Pi 5, but results may vary depending on different setups and use cases.
I encourage you to take these ratings with a grain of salt and experiment for yourself to see what works best for your needs.
| LLM | Ratings |
| Gemma 2 (2b) | ⭐⭐⭐⭐ |
| Qwen 2.5 (3b) | ⭐⭐⭐⭐⭐ |
| Phi 3.5 (3.8b) | ⭐⭐ |
| Mistral (7b) | ⭐⭐⭐ |
| Llama 2 (7b) | – |
| Codellama (7b) | – |
| Nemotron-mini (4b) | ⭐⭐⭐⭐ |
| Orca-mini (3b) | ⭐⭐⭐ |
| Codegemma (2b) | ⭐ |
Final Thoughts
Testing a wide range of LLMs on the Raspberry Pi 5 has provided valuable insights into the kinds of models that can realistically run on this compact device.
In general, models under 7 billion parameters are well-suited for the Pi, offering a good balance between performance and resource usage.
However, there are exceptions like Mistral 7B, which, despite being a larger model, ran fine albeit a bit slow.
Models in the 2B, 3B, and 4B range, on the other hand, performed exceptionally well, demonstrating the Pi’s capability to handle sophisticated AI tasks.
As we continue to advance in the field of AI, I believe we’ll see more models being optimized for smaller devices like the Raspberry Pi.
What do you think? Are there any models you’re trying out on your Pi? Do let us know!