
What is MLflow? | Ubuntu
MLflow is an open source platform, used for managing machine learning workflows. It was launched back in 2018 and has grown in popularity ever since, reaching 10 million users in November 2022. AI enthusiasts and professionals have struggled with experiment tracking, model management and code reproducibility, so when MLflow was launched, it addressed pressing problems in the market. MLflow is lightweight and able to run on an average-priced machine. But it also integrates with more complex tools, so it’s ideal to run AI at scale.
History of MLflow
Since MLflow was first released in June 2018, the community behind it has run a recurring survey to better understand user needs and ensure the roadmap s address real-life challenges. About a year after the launch, MLflow 1.0 was released, introducing features such as improved metric visualisations, metric X coordinates, improved search functionality and HDFS support. Additionally, it offered Python, Java, R, and REST API stability.
MLflow 2.0 landed in November 2022, when the product also celebrated 10 million users. This version incorporates extensive community feedback to simplify data science workflows and deliver innovative, first-class tools for MLOps. Features and improvements include extensions to MLflow Recipes (formerly MLflow Pipelines) such as AutoML, hyperparameter tuning, and classification support, as well as improved integrations with the ML ecosystem, a revamped MLflow Tracking UI, a refresh of core APIs across MLflow’s platform components, and much more.
In September 2023, Canonical released Charmed MLflow, a distribution of the upstream project.
Why use MLflow?
MLflow is often considered the most popular ML platform. It enables users to perform different activities, including:
- Reproducing results: ML projects usually start with simplistic plans and tend to go overboard, resulting in an overwhelming quantity of experiments. Manual or non-automated tracking implies a high chance of missing out on finer details. ML pipelines are fragile, and even a single missing element can throw off the results. The inability to reproduce results and codes is one of the top challenges for ML teams.
- Easy to get started: MLflow can be easily deployed and does not require heavy hardware to run. It is suitable for beginners who are looking for a solution to better see and manage their models. For example, this video shows how Charmed MLflow can be installed in less than 5 minutes.
- Environment agnostic: The flexibility of MLflow across libraries and languages is possible because it can be accessed through a REST API and Command Line Interface (CLI). Python, R, and Java APIs are also available for convenience.
- Integrations: While MLflow is popular in itself, it does not work in a silo. It integrates seamlessly with leading open source tools and frameworks such as Spark, Kubeflow, PyTorch or TensorFlow.
- Works anywhere: MLflow runs on any environment, including hybrid or multi-cloud scenarios, and on any Kubernetes.
MLflow components
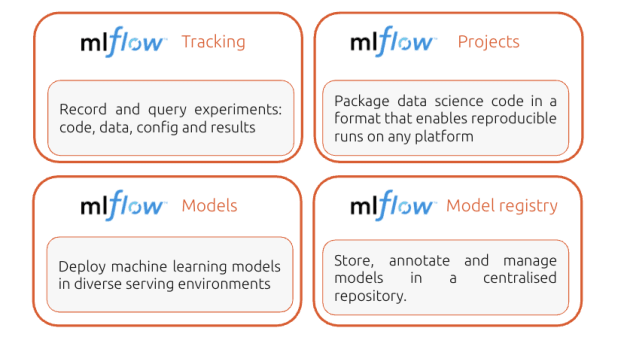
MLFlow is an end-to-end platform to manage the machine learning lifecycle. It has four primary components:
- Tracking: Allows you to track experiments to record and compare parameters and results.
- Models: Allow you to manage and deploy models from various ML libraries to various model serving and inference platforms.
- Projects: Allow you to package ML code in a reusable, reproducible form to share with other data scientists or transfer to production.
- Model Registry: Allows you to centralise a model store for managing models’ full lifecycle stage transitions: from staging to production, with capabilities for versioning and annotating. Databricks provides a managed version of the Model Registry in Unity Catalog.
MLflow Tracking
MLflow Tracking is used to track different pipeline parameters such as metrics, hyperparameters, feature parameters, code versions, and other artifacts. The logs can later be used to visualise or compare the results between experiments, users, or environments. The logs can be stored both on any local system and remote servers.
MLflow Models
With MLflow Models, the ML model can be packaged into different formats or structures. For example, a format or structure such as a TensorFlow DAG or a Python function, and the descriptor file defines it. This ability to package different formats enables the model to be used across a host of downstream tools and platforms, such as on Docker or AWS SageMaker. This makes the model lifecycle easier to process and manage.
MLflow projects
MLflow Projects offer a convention for packaging or structuring your ML projects and reusable project codes. Fundamentally, a project is a directory along with a descriptor file that defines the structure and dependencies. Additionally, on using the MLflow API in the project, MLflow automatically remembers the parameters or project details.
MLflow model registry
MLflow Registry acts as a core and enables APIs, UI, and centralised model storage. It aims to govern the end-to-end ML pipeline through tracking model lineage and versioning capabilities.
Key concepts of MLflow
MLflow is built around two key concepts: runs and experiments.
- An MLflow run corresponds to a single execution of model code. All MLflow runs are logged to the active experiment. If no active experiment is set, runs are logged to the notebook experiment.
- An MLflow experiment is the primary unit of organisation and access control for MLflow runs; all MLflow runs belong to an experiment. Experiments let you visualise, search for, and compare runs, as well as download run artifacts and metadata for analysis in other tools.
Kubeflow vs MLflow

Both Kubeflow and MLFlow are open source solutions designed for the machine learning landscape. They received massive support from industry leaders, and are driven by a thriving community whose contributions are making a difference in the development of the projects. The main purpose of both Kubeflow and MLFlow is to create a collaborative environment for data scientists and machine learning engineers, and enable teams to develop and deploy machine learning models in a scalable, portable and reproducible manner.
However, comparing Kubeflow and MLflow is like comparing apples to oranges. From the very beginning, they were designed for different purposes. The projects evolved over time and now have overlapping features. But most importantly, they have different strengths. On the one hand, Kubeflow is proficient when it comes to machine learning workflow automation, using pipelines, as well as model development. On the other hand, MLFlow is great for experiment tracking and model registry. From a user perspective, MLFlow requires fewer resources and is easier to deploy and use by beginners, whereas Kubeflow is a heavier solution, ideal for scaling up machine learning projects.
Charmed MLflow vs the upstream project
Charmed MLflow is Canonical’s distribution of the upstream project. It is part of Canonical’s growing MLOps portfolio. It has all the features of the upstream project, to which we add enterprise-grade capabilities such as:
- Simplified deployment: the time to deployment is less than 5 minutes, enabling users to also upgrade their tools seamlessly.
- Simplified upgrades using our guides.
- Automated security scanning: The bundle is scanned at a regular cadence..
- Security patching: Charmed MLflow follows Canonical’s process and procedure for security patching. Vulnerabilities are prioritised based on severity, the presence of patches in the upstream project, and the risk of exploitation.
- Maintained images: All Charmed MLflow images are actively maintained.
- Comprehensive testing: Charmed MLflow is thoroughly tested on multiple platforms, including public cloud, local workstations, on-premises deployments, and various CNCF-compliant Kubernetes distributions.