Regular Expressions in Grep – LinuxWays
Regular Expressions (Regex): Regular expression is a very powerful search mechanism and pattern that we use to manipulate and match the text. Regular expressions and a sequence of different or similar characters are used to define our search pattern. When we use it with tools like sed, grep, or some programming languages like Python, regular expressions enable us to search, match, and manipulate strings in a flexible and very efficient way.
Now let’s talk about grep. Grep is a command-line tool that is available in almost every Unix-based system and some other operating systems out there. One of the primary purposes of using this tool is to search for certain text patterns in files or data streams. When we combine it with our regular expressions, grep becomes and acts like a versatile tool for searching and filtering text for us.
How to Use Regular Expression?
Basic Usage: The basic syntax of grep is as follows:
grep [options] pattern [file(s)]
- pattern: Here the pattern is the regular expression or the string we want to search for in our system.
- file(s): This is the destined file or list of our files in which we want to search for a particular pattern. If we do not specify it, the grep will search the standard input
There are several options that also get used with our regular expressions and grep. Some of them are as follows.
- -i: Ignore case, our pattern will match regardless of the letter case.
- -v: Invert the match, it shows those lines in the file that do not match the pattern.
- -r: it recursively searches the directories for the needed pattern for us.
- -n: It shows line numbers in our file along with matching lines.
- -E (or –extended-regexp): it uses extended regular expressions.
Examples of Regular Expression
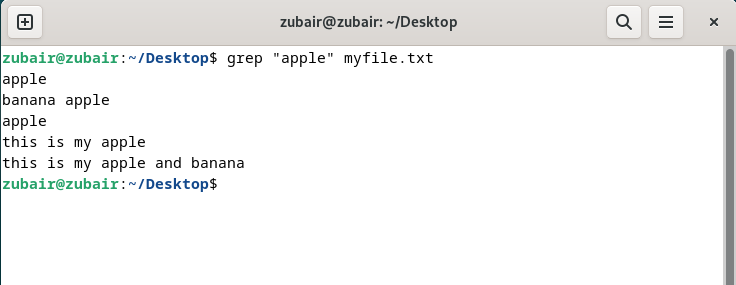
Let’s search for the word “apple” in our file named myfile.txt and it is on our Desktop in Debian 12. But first, let’s move to Desktop with the cd command.
So here, let’s search for the word “apple” ignoring the case:
$ grep “apple” myfile.txt
Now let’s try to have another example and this time let’s search for the banana but this time, we will ignore the case and we will also see the line number as well.
$ grep -i -n “banana” myfile.txt

Now let’s search for those lines in our file that start with “hello”
$ grep “^hello” myfile.txt

We have only one line here that starts with hello
This time, let’s search for lines that are ending with “hello”
$ grep “hello$” myfile.txt

Let’s have another example in which we will be searching for lines containing either “cat” or “dog”:
$ grep “cat|dog” myfile.txt

These are just basic examples to get you started. In certain cases, we can have regular expressions that are a bit complex yet powerful. It allows us to perform sophisticated searches and text manipulations.
Regular expressions are often used to match specific patterns, like IP addresses. Every IP address has four sets of numbers separated by dot and ranges from 0 to 255 separated by dots. Here’s how you can use grep to find IP addresses in a file:
$ grep -Eo ‘([0-9]{1,3}.){3}[0-9]{1,3}’ myfile.txt

Email addresses follow specific patterns. Here’s how you can use grep to find email addresses in a file:
$ grep -Eo ‘[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}’ myfile.txt

Conclusion
Regular expressions (regex) are a powerful way and tool for us to search certain patterns, match them, and we can also use it to manipulate the text. We widely use it to find specific patterns in our files and directories in our Linux distributions. When we combine it with the grep command, it becomes even more versatile and powerful, which allows us to perform advanced searches and filtering tasks efficiently.
We have seen several examples in this article which depict how we can use regular expressions with grep. These examples included searching for some specific words, matching different lines starting or ending with certain patterns, and finding complex patterns such as IP addresses and email addresses.